MySQL is a widely used open-source relational database management system. As much as this RDBMS is widely used though, in certain aspects it is frequently misunderstood. One of those aspects is big data – should you run big data applications on MySQL? Should you use MongoDB? Maybe you should take a look at neo4j or even AWS Redshift? We will try to explore that in this post.
Understanding MySQL and Big Data
Before we begin diving deeper into MySQL and big data, we should probably figure out what MySQL is and how it works first. Here’s the crux of it:
- MySQL is an open-source RDBMS that can be installed on any server.
- The task of MySQL is to create and manage databases and tables inside them used to store and / or manipulate information.
- The performance of MySQL can be significantly impacted by its configuration which can be either left at default or changed.
- Information inside MySQL is manipulated using a language called SQL which translates to Structured Query Language.
- When an SQL statement is run through a database, the database reads through each record and matches a given expression to the fields.
Big data, on the other hand, is a term that usually emphasizes a large volume of data. As such, the data could not be suitable for traditional storage and processing methods.
Understanding MySQL internals
When using MySQL, there are a few storage engines to choose from:
- InnoDB – the default storage engine for MySQL 5.5 and higher. Supports transactions, row-level locking and foreign keys;
- MyISAM – this storage engine manages non-transactional tables and supports full-text searching;
- MEMORY – this storage engine stores all data in memory, hence the name;
- BLACKHOLE – a /dev/null storage engine. Accepts data but does not store it;
- CSV – an engine that stores data in text-files using a comma-separated values format;
- ARCHIVE – a storage engine that produces special-purpose tables that store large amounts of unindexed data in a very small footprint;
- FEDERATED – a storage engine that enables data access from a remote MySQL database without using replication or clustering.
Though there are a lot of options, the two most commonly used storage engines in MySQL are InnoDB and MyISAM. The main differences between those two are as follows:
- InnoDB has row-level locking, MyISAM only has table-level locking;
- InnoDB has better data integrity and crash recovery (this is one of the reasons why MyISAM is sometimes referred to as an “unreliable” storage engine);
- InnoDB did not support FULLTEXT search indexes until MySQL 5.6, MyISAM supports them by default;
- InnoDB utilizes the InnoDB buffer pool which caches data and indexes of its tables, MyISAM utilizes the key cache.
InnoDB is also ACID compliant.
ACID?

In regards to database systems, ACID is a set of properties that aims to guarantee data validity in case of any kind of failures that might occur while processing a database transaction. A database management system that adheres to these principles is referred to as an ACID-compliant DBMS.
ACID is an acronym that breaks down as follows:
- Atomicity ensures that the statements in a transaction operate as an indivisible unit and that their effects are seen either collectively or not at all;
- Consistency is handled by MySQL’s logging mechanisms which record all changes to the database;
- Isolation refers to InnoDB’s row-level locking;
- Durability refers to a maintenance of a log file that tracks all of the changes to the system.
The correct choosing of a database engine is crucial to any kind of project – especially to the projects that deal with such volumes of data on a regular basis, so if we’re dealing with big data on MySQL we should probably choose InnoDB.
Diving deeper into InnoDB
Now we know what a DBMS is, what are the choices of database engines when dealing with MySQL, what is ACID compliance and why you should choose InnoDB when dealing with data, but we have just scratched the surface – in order to better understand how InnoDB works, we must take a closer look at the engine. Here’s how InnoDB looks under the hood:
The above diagram depicts the complexity of InnoDB. Let’s break it down starting from the memory part:
- We can see that the buffer pool is a huge part of InnoDB’s memory – that is because of the fact that innodb_buffer_pool_size is arguably the most important variable when dealing with InnoDB: it’s a memory buffer that InnoDB uses to cache data and indexes of its tables. The buffer pool is comprised of multiple buffers including the change and insert buffers;
- The log buffer is also very important – the larger this value is (it is recommended to set this value between 4 and 16MB in size) the less recovery time you will need in case of a crash;
- On the memory side, we also have some miscellanous internal memory things – we have the page hash (a database page is a basic structure to organize the data in the database files), the file, log and recovery systems and threads;
- Values from the log buffer are written to the log file according to the fsync method. There are two values that can be set in this scenario – turning innodb_flush_log_at_trx_commit to 2 gets a very fast write speed, but can lose up to one second’s worth of transactions. The default value is 1, which helps keep InnoDB ACID compliant.
On the disk side of InnoDB we see its system tablespace – the ibdata1 file is arguably the busiest file in the InnoDB infrastructure as it contains all of the tables and indexes in a database. It contains:
- Table data and indexes;
- Multiversioning Concurrency Control (MVCC) data;
- Rollback segments;
- Undo space;
- The data dictionary (table metadata);
- Double write and insert buffers.
The major problem with this file is that it can only grow – even if you drop a table associated with an InnoDB engine, ibdata1 will not get smaller and if you delete the ibdata1 file, you delete all of the data associated with InnoDB tables. This can become an extremely huge and frustrating problem when dealing with big data on MySQL – if you run MySQL without looking at this, you risk losing a lot of disk space for nothing. The only way to shrink this file once and for all and to clean InnoDB infrastructure is to:
- Dump all databases;
- Drop all databases except for mysql and information_schema;
- Login to MySQL and run SET GLOBAL innodb_fast_shutdown = 0; to completely flush all remaining transactional changes from the log files (ib_logfile0 and ib_logfile1);
- Shut down MySQL;
- Add the following lines to /etc/my.cnf (the following configuration is only available in Linux since O_DIRECT is not available on Windows machines):
innodb_file_per_table;
innodb_flush_method = O_DIRECT;
innodb_buffer_pool_size = 10G;
innodb_log_file_size = 2.5G;
Note: make sure that innodb_log_file_size is 25% of the innodb_buffer_pool_size. - Delete the ibdata* and ib_logfile* files. You can also remove all folders in /var/lib/mysql directory (except the MySQL folder).
Starting MySQL at this point will recreate ibdata1, ib_logfile0 and ib_logfile1 at 2.5GB each.
When you accomplish this ibdata1 will grow, but will only contain table metadata without InnoDB table data and without indexes for its tables – the tables will be represented in .frm and .ibd files respectively.
Each .frm file will contain the storage engine header and the .ibd file will contain the table data and indexes. This way, if you would want to remove a table from an InnoDB engine, you would simply delete the associated .ibd and .frm files.
At this point, you probably notice that we have touched a few InnoDB parameters without fully explaining what they are or what they do. The major parameters we need to take a look at are as follows:
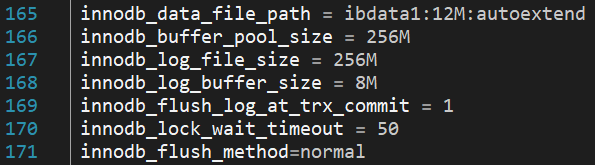
The above illustration depicts all of the major parameters when dealing with InnoDB:
- The innodb_data_file_path parameter refers to a file where data from InnoDB tables will be stored;
- innodb_buffer_pool_size is a memory buffer that InnoDB uses to cache data and indexes of its tables;
- The larger innodb_log_file_size is, the less recovery time you need in case of a crash;
- InnoDB uses innodb_log_buffer_size to write to the log files on disk;
- Turning innodb_flush_log_at_trx_commit to 2 gets a very fast write speed, but can lose up to one second’s worth of transactions. The default value is 1, which helps keep InnoDB ACID compliant;
- innodb_lock_wait_timeout defines the length of time in seconds an InnoDB transaction waits for a row lock before giving up. The default value is 50 seconds;
- innodb_flush_method defines the method used to flush data to InnoDB data and log files which can affect I/O throughput.
When dealing with big data on an InnoDB-based infrastructure we need to change these parameters quite a bit. Obviously, if we run big data applications in any kind of environment, we need appropriate servers with a lot of disk space and increased RAM. We should also choose the flavor of an operating system in our server.
We will take a look at what the my.cnf configuration could be on a server environment that has one 1TB disk and 8GB of RAM available.
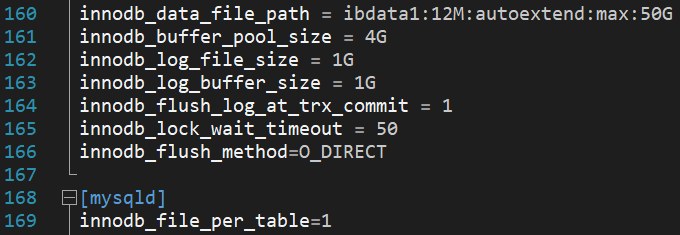
As this is a machine with 8GB of RAM available, we would also be able to set innodb_buffer_pool_size to a higher value – approximately 6 to 6.5GB (no more than about 80% of RAM size) and adjust innodb_log sizes accordingly.
InnoDB Flush Methods
From the picture above we can also see that innodb_file_per_table is now enabled and the innodb_flush_method is set to O_DIRECT. We have stated before that O_DIRECT is not available on Windows machines and that is because of the fact that Windows uses async_unbuffered causing this variable to have no effect. If we’re dealing with Windows, the only recognized innodb_flush_method values are “normal”, “unbuffered” and “async_unbuffered”. On Unix machines on the other hand, we can use “fsync”, “O_DSYNC”, “littlesync”, “nosync”, “O_DIRECT” and “O_DIRECT_NO_FSYNC”. Here’s what all of the flush method variables do:
- normal – InnoDB will use simulated asynchronous I/O and buffered I/O;
- unbuffered – InnoDB will use simulated asynchronous I/O and non-buffered I/O;
- async_unbuffered – InnoDB will use Windows asynchronous I/O and non-buffered I/O. Default setting on Windows machines;
- fsync – InnoDB will use the fsync() system call to flush the data and the log files. Default setting on Linux machines;
- O_DSYNC – InnoDB will use O_SYNC to open and flush the log files, fsync() to flush the data files. It is worth noting that the O_DSYNC variable is not used directly because there have been problems with the setting on varieties of Unix;
- littlesync – used for internal performance testing;
- nosync – used for internal performance testing;
- O_DIRECT – InnoDB will use O_DIRECT to open the data files and fsync() to flush both data and log files. The OS cache will be avoided;
- O_DIRECT_NO_FSYNC – InnoDB will use O_DIRECT during flushing I/O, but the fsync() call will be skipped.
The fsync() system call is closely related to a standard system call in the Unix architecture – sync(). The call commits all data which has been scheduled for writing via low-level I/O system calls. fsync() commits just the buffered data relating to a specified file descriptor (an indicator or handle used to access resources). In other words, this call will only return after the data and metadata is transferred to the actual physical storage.
At this point, MySQL is almost ready to deal with big data! There are a few more things we need to cover though – the table design, loading big data sets into the tables and replication.
Uploading Big Data into MySQL
It usually isn’t a very big problem to load data into MySQL – you just upload a dump into the database, that’s it. Problems start when the data sets start getting bigger – when loading such data into MySQL the upload starts timing out and if it does not time out, the upload takes an incredibly long time.
The reason why this is happening is because an INSERT statement has a significant amount of overhead including locking, transaction demarcation, integrity checks, allocation of resources and a per-statement basis I/O. We can avoid that by using bulk loading – bulk loading can be hundreds of times faster than INSERT statements because it is specifically designed for loading massive amounts of data.
Although bulk loading is designed for massive amounts of data, if the data you’re loading into the system has millions of rows, bulk loading can significantly slow down. This can be the case if your bulk insert buffer size is too small – such a scenario is known as bulk insert buffering. To fix this, increase the bulk_insert_buffer_size setting.
Query Speed
Even if all of your database settings are properly optimized, queries on big data can still be really slow. To improve query speed:
- Use partitions – partitioning enables MySQL to split the data into separate tables, but still treat the data as being in a single table by the SQL layer;
- Make use of indexes – indexing makes the queries that use the index faster because it avoids a full table scan;
- Utilize normalization – normalization is the process of structuring a relational database in such a manner that reduces data redundancy and improves data integrity;
- If possible, avoid using
ALTER TABLE– a very large table will take a very long time toALTERbecause MySQL has to read-lock the table, create a temporary table with the desired structure, copy all rows to that temporary table, unlock the table to reads and delete the old table; - Take a look at query profiling – query profiling can display profiling information that indicates resource usage for statements executed when profiling was enabled. This can be useful when identifying bottlenecks in query performance.
Replication and Backups
Replication enables data from one MySQL database server to be copied to one or more database servers. The main database server is referred to as the master, the others are referred to as the slaves. This can be useful dealing with any amount of data, especially if developers are using MySQL to host massive data sets. Replication can be used for a number of reasons including improving performance by distributing load across multiple server nodes or backing up data. There are multiple types of replication:
- Master-slave replication enables data from one database server (the master) to be replicated to one or more database servers (the slaves);
- Master-master replication is master-slave replication, but the master database is made to be a slave to the original slave database so each master is also a slave;
- MySQL cluster is a technology that is designed to provide high availability and throughput with low latency allowing for near linear scalability.
Each replication type, of course, has its own pros and cons meaning that they could be suited for different types of usage.
Master-slave Replication
Master-slave replication could be useful if developers have the need for reading from the slaves without impacting the master or if the developers don’t want the backups on the database leaving an impact on the master. Master-slave replication is also useful if slaves need to be taken offline and synchronized with the master without downtime.
However, the main con with master-slave replication is that in the instance of master database failure, a slave server has to be promoted to a master server manually meaning that you could risk some downtime.
Master-master Replication
Master-master replication can be useful if developers need their application to distribute load or read from both master servers. Master-master replication also comes with automatic failover.
However, the configuration of a master-master architecture is more difficult than configuration of a master-slave architecture.
MySQL Cluster
Using a MySQL cluster can be useful if an application requires high availability, uptime and throughput or distributed writes, however, there are quite a few limitations of such an architecture.
MyISAM?
At this point, you could notice that we haven’t touched one of MySQL engines – MyISAM. We did not do that because if you run both InnoDB and MyISAM engines the process of getting them both to work together will be tedious – you’re going to need to consider allocating memory for each of the engines, since each of them has its own caching.
Summary
To summarize, MySQL is perfectly capable of working with big data sets – however, the performance you will get will heavily depend on what servers you will use, whether you will use them to their full potential or not (you might not need a terabyte of RAM – maybe 32GB or even 16GB would suffice), to what extent will you optimize MySQL, what database engine will you use and how good of a MySQL DBA you are.