MySQL yra plačiai naudojama atvirojo kodo reliacinių duomenų bazių valdymo sistema. Nors ši RDBVS yra plačiai naudojama, tam tikrais aspektais ji dažnai suprantama neteisingai. Vienas iš tų aspektų yra dideli duomenys – ar reikėtų naudoti didelių duomenų aplikacijas MySQL infrastruktūroje? Galbūt turėtumėte naudoti MongoDB? Gal reikėtų peržvelgti neo4j ar net AWS Redshift? Pabandysime į tai pažvelgti išsamiau.
Kas yra MySQL ir Dideli Duomenys?
Prieš pradėdami gilintis į MySQL ir didelius duomenis, turbūt turėtume išsiaiškinti, kas yra MySQL ir kaip tai veikia:
- MySQL yra atvirojo kodo reliacinė duomenų bazių valdymo sistema, kurią galima įdiegti į bet kurį serverį.
- MySQL uždavinys yra kurti ir valdyti duomenų bazes ir juose esančias lenteles, kurios yra naudojamos saugoti ir (arba) manipuliuoti informacija.
- MySQL veikimui itin didelę įtaką gali turėti jos konfigūracija, kuri gali būti keičiama.
- Informacija esanti MySQL sistemoje manipuliuojama naudojant SQL programavimo kalbą.
- Kai SQL užklausa pasiekia duomenų bazę, duomenų bazė perskaito kiekvieną joje esantį įrašą ir tinkina nurodytą užklausos išraišką su duomenų bazėje esančiais laukais.
Kita vertus, dideli duomenys yra ganėtinai platus terminas kuris paprastai apibrėžia didelį duomenų kiekį – tokie duomenys gali būti netinkami tradiciniams duomenų saugojimo ir apdorojimo metodams taikyti.
MySQL iš vidaus
Naudodami MySQL galite naudoti kelis saugyklų variklius:
- InnoDB – numatytasis MySQL 5.5 ir naujesnių versijų variklis. Palaiko operacijas, eilučių lygio užrakinimus ir svetimus raktus;
- MyISAM – šis variklis valdo ne transakcijų lenteles ir palaiko “Full-text” paiešką;
- MEMORY – Šis variklis visus duomenis saugo atmintyje;
- BLACKHOLE – /dev/null saugojimo variklis. Priima duomenis, bet jų nesaugo;
- CSV – variklis, kuris duomenis saugo tekstiniuose failuose naudodamas formatą, perskiriantį laukus kableliais;
- ARCHIVE – variklis, kuris gamina specialios paskirties lenteles, kuriose kaupiami dideli kiekiai neindeksuotų duomenų. Vartotojai gali naudoti šį variklį norėdami sukurti lentelę, naudojamą archyvams.
- FEDERATED – variklis, kuris leidžia pasiekti duomenis iš nuotolinės MySQL duomenų bazės nenaudojant replikacijos ar grupiavimo.
Nors pasirinkimų yra ganėtinai daug, du dažniausiai naudojami MySQL varikliai yra InnoDB ir MyISAM. Pagrindiniai skirtumai tarp šių dviejų variklių yra:
- InnoDB turi lentelės lygio užraktus, MyISAM – tik staliukų lygio;
- InnoDB turi geresnį duomenų vientisumą ir gedimų atkūrimą (tai yra viena iš priežaščių, kodėl MyISAM kartais yra vadinamas “nepatikimu” varikliu);
- InnoDB nepalaikė FULLTEXT paieškos indeksų iki MySQL 5.6, MyISAM palaiko juos pagal nutylėjimą;
- InnoDB naudoja InnoDB “buffer pool”, kuriame kaupiami duomenys ir lentelių indeksai, MyISAM naudoja “key buffer” arba “key cache”.
InnoDB taip pat atitinka ACID parametrus.
ACID?

Kai kalbame apie duomenų bazių sistemas, ACID yra savybių rinkinys, kuriuo siekiama užtikrinti duomenų integralumą bet kokių nesklandumų, galinčių kilti apdorojant duomenų bazių operacijas, atvejais. Duomenų bazės valdymo sistema, kuri laikosi šių principų, yra vadinama ACID atitinkančia DBVS.
ACID yra santrumpa išskaidoma taip:
- Atomicity (atomumas) užtikrina, kad užklausos veiktų kaip nedalomi vienetai ir kad jų poveikis būtų matomas kartu arba visai nematomas;
- Consistency (nuoseklumas) priskiriamas MySQL registravimo mechanizmams, kurie registruoja visus pakitimus duomenų bazėje;
- Isolation (izoliacija) reiškia InnoDB eilučių lygio užraktą;
- Durability (patvarumas) reiškia log failo, kuriame surašyti visi sistemos pakitimai, palaikymą.
Teisingas duomenų bazės variklio pasirinkimas yra labai svarbus bet kokio tipo projektui – tai ypač svarbu tiems projektams, kurie tvarko didelius duomenų kiekius, taigi, jei kalbame apie didelius duomenis MySQL infrastruktūroje, turėtume pasirinkti InnoDB.
InnoDB Infrastruktūra
Dabar mes žinome, kas yra DBVS, kokius duomenų bazių variklius galima pasirinkti dirbant su MySQL, kas yra ACID ir kodėl dirbdami su duomenimis turėtume pasirinkti InnoDB, tačiau mes pamatėme tik ledkalnio viršūnę – norėdami geriau suprasti kaip InnoDB veikia, privalome atidžiau pažvelgti į variklį. Štai kaip po gaubtu atrodo InnoDB:
Aukščiau pateikta schema yra vaizdinis InnoDB architektūros pavyzdys. Panagrinėkime ją išsamiau pradėdami nuo atminties:
- Matome, kad “buffer pool” yra didžiulė InnoDB atminties dalis – taip yra todėl, kad innodb_buffer_pool_size yra pats svarbiausias InnoDB parametras: tai atminties buferis, kurį InnoDB naudoja tam, kad talpintų duomenis ir lentelių indeksus. Buffer pool sudaro keli buferiai įskaitant keitimo ir įterpimo buferius;
- Log (įrašų) buferis taip pat yra labai svarbi InnoDB dalis – kuo didesnė šio kintamojo vertė (rekomenduojama nustatyti šio kintamojo reikšmę nuo 4 iki 16MB), tuo mažiau atkūrimo laiko reikės duomenų bazės veiklai sutrikus;
- Atinties pusėje taip pat turime keletą įvairių vidinės atminties dalykų – turime puslapio (duomenų bazės puslapis yra pagrindinė struktūra duomenims duomenų bazės failuose tvarkyti) “hash” (maišos funkciją), failų, įrašų (log) ir atkūrimo sistemas bei gijas;
- Vertės iš log (įrašų) buferio yra įrašomos į log failą atsižvelgiant į fsync metodą. Šis kintamasis gali turėti dvi vertes – pakeitus innodb_flush_log_at_trx_commit į 2 gausime labai greitą įrašymo greitį, tačiau galime prarasti iki vienos sekundės vertės operacijų. Pagal nutylėjimą šio kintamojo vertė yra 1 – tai padeda InnoDB išlaikyti ACID suderinamumą.
InnoDB disko pusėje matome sistemos “tablespace” (lentelių erdvę) – ibdata1 failas yra labiausiai užimtas vailas visoje InnoDB infrastruktūroje, nes jame yra visos duomenų bazėje esančios lentelės ir indeksai. Jame yra:
- Lentelių duomenys ir indeksai;
- Multiversioning Concurrency Control (MVCC) duomenys;
- Atstatymo segmentai;
- Anuliuota duomenų bazės erdvė;
- Duomenų žodynas (lentelių metaduomenys);
- Double write ir įrašymo buferiai.
Pagrindinė šio failo problema yra ta, kad jis gali tik augti – net jei ir ištrinsite lentelę susietą su InnoDB varikliu, ibdata1 failo dydis nesumažės, o jei ištrinsite ibdata1 failą, ištrinsite visus duomenis, susijusius su InnoDB lentelėmis. Tai gali tapti nepaprastai didele ir varginančia problema kai dirbama su dideliais duomenų kiekiais – jei paleisite MySQL pražiūrėję šią problemą, rizikuojate prarasti daug vietos diske veltui. Vienintelis būdas sumažinti šio failo dydį kartą ir visiems laikams ir išvalyti InnoDB infrastruktūrą yra:
- Pasidaryti duomenų kopiją;
- Sunaikinti visas duomenų bazes išskyrus mysql ir information_schema;
- Prisijungti prie MySQL ir paleisti užklausą tam, kad iš log failų (ib_logfile0 ir ib_logfile1) būtų visiškai išvalyti visi likę operacijų pakeitimai;
- Išjungti MySQL;
- Įtraukti šias eilutes į /etc/my.cnf (ši konfigūracija veiks tik Linux architektūroje, nes O_DIRECT nėra prieinama Windows operacinėse sistemose):
innodb_file_per_table;
innodb_flush_method = O_DIRECT;
innodb_buffer_pool_size = 10G;
innodb_log_file_size = 2.5G;
Pastaba: įsitikinkite, kad innodb_log_file_size yra 25% viso innodb_buffer_pool_size. - Delete the ibdata* and ib_logfile* files. Taip pat galite ištrinti visas direktorijas esančias /var/lib/mysql direktorijoje (išskyrus MySQL direktoriją).
Po šios operacijos paleidę MySQL pastebėsite, kad ibdata1, ib_logfile0 ir ib_logfile1 failai bus 2.5GB dydžio.
Kai tai atliksite, ibdata1 failas augs, tačiau šiame faile bus tik lentelių metaduomenys be InnoDB lentelės duomenų ir be lentelių indeksų – lentelės bus reprezentuojamos .frm ir .ibd failuose.
Kiekviename .frm faile bus saugojimo variklio antraštė, o .ibd faile bus lentelės duomenys ir indeksai. Jei norėsite pašalinti lentelę su InnoDB varikliu tiesiog ištrinsite susijusius .ibd ir .frm failus.
Tikriausiai pastebėjote, kad palietėme kelis InnoDB parametrus iki galo nepaaiškinę kas jie yra ar ką jie daro. Pagrindiniai parametrai į kuriuos turime pažvelgti yra šie:
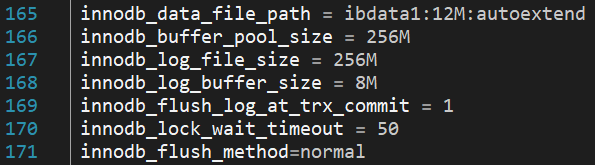
Aukščiau pavaizduotame paveikslėlyje pavaizduoti visi pagrindiniai InnoDB parametrai:
- Parametras innodb_data_file_path nurodo failą, kuriame bus saugomi InnoDB lentelių duomenys;
- innodb_buffer_pool_size yra atminties buferis, kurį InnoDB naudoja lentelių duomenims ir indeksams kaupti;
- Kuo didesnis innodb_log_file_size dydis, tuo mažiau atkūrimo laiko reikės duomenų bazės veiklai sutrikus;
- InnoDB naudoja innodb_log_buffer_size tam, kad įrašytų informaciją į log failus esančius diske;
- Pakeitus innodb_flush_log_at_trx_commit į 2 gaunamas labai greitas rašymo greitis, tačiau galima prarasti iki vienos sekundės užklausos vertės įrašų. Pagal nutylėjimą ši reikšmė yra 1, tai padeda InnoDB išlaikyti ACID suderinamumą;
- innodb_lock_wait_timeout apibrėžia laiką sekundėmis, per kurį InnoDB operacija laukia eilutės užrakto prieš atsisakydama atlikti užklausą. Numatytoji vertė yra 50 sekundžių;
- innodb_flush_method nurodo metodą, kuris yra naudojamas norint įrašyti duomenis į InnoDB ir log failus – gali turėti įtakos I/O pralaidumui.
Kai dirbame su dideliais duomenų kiekiais InnoDB infrastruktūroje, šiuos parametrus turime šiek tiek pakeisti. Akivaizdu, kad jei bet kokioje aplinkoje dirbame su itin dideliais duomenų kiekiais, mums reikia atitinkamų serverių, daug disko vietos ir ganėtinai daug RAM atminties. Taip pat turėtume pasirinkti serveryje esančią operacinę sistemą.
Pažvelgsime į serveryje su 1TB disku ir 8GB operatyviosios atminties esančią my.cnf konfigūraciją.
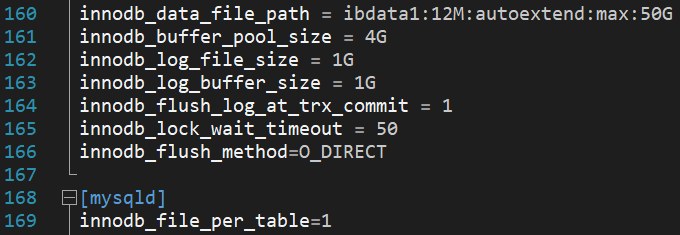
Kadangi šis serveris turi 8GB operatyviosios atminties, mes taip pat galėtume nustatyti innodb_buffer_pool_size į didesnę vertę – šiuo atveju šio kintamojo vertė gali būti apytiksliai nuo 6 iki 6.5GB (ne daugiau kaip apie 80% operatyviosios atminties dydžio). Turėtume atitinkamai pakoreguoti ir innodb_log dydžius.
InnoDB Flush Metodai
Aukščiau pateiktame paveikslėlyje taip pat matome, kad innodb_file_per_table direktyva yra įjungta ir innodb_flush_method yra nustatytas į O_DIRECT. Ankščiau sakėme, kad O_DIRECT nėra prieinamas Windows operacinėse sistemose ir taip yra todėl, kad Windows naudoja async_unbuffered, todėl ši kintamojo reikšmė neturi jokio poveikio. Jei kalbame apie Windows, vienintelės priimtinos innodb_flush_method reikšmės yra “normal”, “unbuffered” ir “async_unbuffered”. Kita vertus, Unix operacinėse sistemose galime naudoti “fsync”, “O_DSYNC”, “littlesync”, “nosync”, “O_DIRECT”, ir “O_DIRECT_NO_FSYNC”. Štai ką daro visi flush metodo kintamieji:
- normal – InnoDB naudos simuliuojamą asinchroninį I/O ir buferinį I/O mechanizmą – toks mechanizmas neleidžia prieš tęsiant įsitikinti, kad reikšmės buvo įrašytos;
- unbuffered – InnoDB naudos simuliuojamą asinchroninį I/O ir nebuferinį I/O mechanizmą – toks mechanizmas leidžia prieš tęsiant įsitikinti, kad reikšmės buvo įrašytos;
- async_unbuffered – InnoDB naudos Windows asinchroninį I/O ir nebuferinį I/O mechanizmą. Šis nustatymas įjungiamas pagal nutylėjimą Windows operacinėse sistemose;
- fsync – InnoDB panaudos fsync() tam, kad įrašytų duomenis ir log failus. Šis nustatymas įjungiamas pagal nutylėjimą Linux operacinėse sistemose;
- O_DSYNC – InnoDB naudos O_DSYNC tam, kad atidarytų ir įrašytų duomenis į log failus, fsync() kad įrašytų duomenis į duomenų failus. Verta paminėti, kad kintamasis O_DSYNC nėra tiesiogiai naudojamas, nes ankščiau šis nustatymas keldavo problemų kai kuriose Unix operacinėse sistemose;
- littlesync – naudojamas sistemų bandymui;
- nosync – naudojamas sistemų bandymui;
- O_DIRECT – InnoDB naudos O_DIRECT duomenų failams atidaryti ir fsync() tam, kad įrašytų duomenis į duomenų ir įrašų failus. Šis nustatymas vengia OS talpyklos (“cache”);
- O_DIRECT_NO_FSYNC – InnoDB naudos O_DIRECT kai atliks I/O operacijas, tačiau fsync() funkcija bus praleista.
fsync() sistemos funkcija yra glaudžiai susijusi su standartine sistemos funkcija Unix architektūroje – sync(). fsync() perduoda tik buferinius duomenis, susijusius su nurodytu failo deskriptoriumi (indikatoriumi, kuris naudojamas prieigai prie resursų). Kitaip tariant, ši funkcija baigsis tik po to kai duomenys ir metaduomenys bus perkelti į faktinę saugojimo vietą.
Dabar MySQL jau yra beveik pasirengusi tvarkyti didelius duomenų kiekius! Beveik – dar yra keletas dalykų, į kuriuos reiktų pažvelgti atidžiau: lentelių dizainas, didelių duomenų įterpimas į lenteles ir replikacija.
Didelių Duomenų Kiekių Įkrovimas į MySQL
Įkelti duomenis į MySQL paprastai nėra labai didelė problema – problemos prasideda tada, kai pradedame dirbti su didesniais duomenų kiekiais – įkeliant tokius duomenis į MySQL užklausos pradeda būti labai lėtos arba nutrūksta.
Taip nutinka todėl, kad kai duomenų bazė apdoroja INSERT užklausą, ji turi apdoroti ir daug pašalinių dalykų įskaitant užrakinimą, operacijų atskyrimą, vientisumo patikrinimus, išteklių paskirstymą, taip pat I/O kiekvienai užklausai. Mes galime to išvengti naudodami masinį duomenų įkrovimą – jis gali būti šimtus kartų greitesnis nei duomenų įkrovimas į duomenų bazę naudojant INSERT užklausas, nes masinis duomenų įkrovimas (bulk loading) yra specialiai sukurtas dideliems duomenų kiekiams.
Nors “bulk loading” yra skirtas dideliems duomenų kiekiams, jei duomenys, kuriuos norite įkelti į sistemą, turi šimtus milijonų įrašų, masinis duomenų įkrovimas gali suletėti. Taip gali nutikti todėl, nes duomenų įkrovimui skirto buferio dydis gali būti per mažas – toks scenarijus yra žinomas kaip “bulk insert buffering”. Norėdami tai išspręsti padidinkite bulk_insert_buffer_size parametro reikšmę.
Užklausų Greitis
Net jei visi duomenų bazės parametrai yra tinkamai optimizuoti, užklausos per didelius duomenis vis tiek gali būti lėtos. Norėdami pagerinti užklausų greitį:
- Naudokite skaidinius (particijas) – skaidymas įgalina MySQL suskaidyti duomenis į atskiras lenteles, tačiau SQL vis tiek traktuoja duomenis kaip esančius vienoje lentelėje;
- Pasinaudoite indeksais – indeksavimas paspartina užklausas kurios naudoja indeksus, taip išvengiama skaitymo iš visos lentelės;
- Panaudokite normalizaciją – normalizavimas yra reliacinių duomenų bazių struktūrizavimo procesas tokiu būdu, kuris sumažina duomenų nereikalingumą ir pagerina duomenų vientisumą;
- Jei įmanoma, venkite naudoti
ALTER TABLE–ALTERužklausos ant labai didelių lentelių dažnai užtrunka labai ilgą laiką, nes MySQL turi užrakinti lentelę skaitymui, sukurti laikiną lentelę su norima struktūra, nukopijuoti visas eilutes į tą laikiną lentelę, atrakinti lentelę ir ištrinti seną lentelę; - Apžvelkite užklausų profiliavimą – užklausų profiliavimas gali pateikti informaciją, nurodančią išteklių naudojimą tada, kai duomenų bazėje aktyvi SQL užklausa. Tai gali būti naudinga nustatant užklausai kylančias kliūtis bei gerinant užklausos greitį.
Replikacija ir Atsarginės Kopijos
Replikacija įgalina duomenų kopijavimą iš vienos MySQL duomenų bazės serverio į vieną ar daugiau duomenų bazių serverių. Pagrindinis duomenų bazės serveris yra vadinamas “pagrindiniu” (“master”), kiti – “vergais” (“slave”). Tai gali būti naudinga dirbant su bet kokiais duomenų kiekiais, ypač jei programuotojai naudoja MySQL darbui su didžiuliais duomenimis. Replikacija gali būti naudojama dėl daugelio priežaščių įskaitant našumo gerinimą paskirstant apkrovą keliems serveriams arba kuriant atsargines duomenų kopijas. Yra keli replikacijos tipai:
- Master-slave replikacija įgalina duomenų iš vienos duomenų bazės serverio replikaciją į vieną ar daugiau duomenų bazių serverių;
- Master-master replikacija yra master-slave replikacija, tačiau “master” serveriai yra sukurti kaip “slave” pirminiams “slave” serveriams, taigi kiekviena “master” duomenų bazė yra ir “slave” duomenų bazė;
- MySQL klasteris yra technologija, kuri sukurta norint užtikrinti aukštą prieinamumą ir pralaidumą su maža latencija, kas leidžia pasiekti beveik tiesinį mastelį. Tiesinis mastelis (angl. “linear scalability”) yra galimybė padidinti gamybos sąnaudas (pvz. pridėti serverių) norint padidinti produkcijos našumą.
Kiekvienas replikacijos tipas, be abejo, turi savo privalumų ir trūkumų – tai reiškia, kad kiekvienas replikacijos tipas tinka skirtingiems naudojimo atvejams.
Master-slave Replikacija
“Master-slave” replikacija gali būti naudinga tada, kai programuotojams reikia skaityti iš “slave” serverių nedarant įtakos “master” serveriui arba jei programuotojai nenori, kad duomenų bazių atsarginės kopijos darytų poveikį “master” serverio veikimui. “Master-slave” replikacija taip pat gali būti naudinga, jei “slave” serveriai turi būti išjungti ir susinchronizuoti su “master” serveriu be prieigos praradimo.
Pagrindinis trūkumas susijęs su “master-slave” replikacija yra tai, kad sugedus “master” duomenų bazei, “slave” serverius reikia padaryti “master” serveriais rankiniu būdu – tai reiškia, kad programuotojai rizikuoja duomenų neprieinamumu.
Master-master Replikacija
“Master-master” replikacija gali būti naudinga, jei programuotojams reikia, kad jų aplikacija paskirstytų apkrovą ar skaitytų iš abiejų “master” serverių. “Master-master” replikacijoje taip pat prieinamas automatinis “failover” – “slave” serverių padarymas “master” serveriais pagrindinei “master” duomenų bazei būnant nebeprieinamai.
Pagrindinis “master-master” replikacijos minusas yra tai, kad šios replikacijos rūšies konfigūracija yra sudėtingesnė nei “master-slave” replikacijos konfigūracija.
MySQL Klasteris
MySQL klasterio naudojimas gali būti naudingas, jei naudojamai aplikacijai reikalingas didelis prieinamumas ir pralaidumas ar paskirstytos įrašymo (“write”) operacijos, tačiau tokia architektūra turi kelis apribojimus.
MyISAM?
Galime pastebėti, kad nelietėme vieno iš MySQL variklių – MyISAM. Mes to nepadarėme, nes jei Jūsų architektūroje bus ir InnoDB ir MyISAM varikliai, priversti abu variklius darniai dirbti bus sudėtinga – tokiu atveju reiktų apsvarstyti kiek atminties skirti kiekvienam varikliui, nes abu varikliai turi skirtingas “cache” talpyklas.
Santrauka
Apibendrinant galima pasakyti, kad MySQL duomenų bazių valdymo sistema tinka dirbti su dideliais duomenų kiekiais, tačiau našumas kurį gausite labai priklausys nuo to, kokius serverius naudosite, ar naudosite juos pilnu pajėgumu, ar ne (jums gali nereikti terabaitų operatyviosios atminties – galbūt pakaktų 32GB ar net 16GB?), kaip optimizuosite MySQL, kokį variklį naudosite ir nuo Jūsų MySQL duomenų bazių administravimo įgūdžių.